所有网站的robots文件都是公开的,如果输入“网站域名/robots.txt”打开了一个404错误页面,则说明该网站没有做robots文件。

robots文件是搜索引擎蜘蛛来一个网站首先要查看的,提前知道该网站哪些允许它抓取,哪些不允许的,它会遵循规定来做。如果不做robots文件,在该网站的空间日志里会出现一个404的错误代码,这不要紧,因为很多网站都不做,尤其对于小型网站并不重要。但大型网站讲究比较细致,基本上都会做。
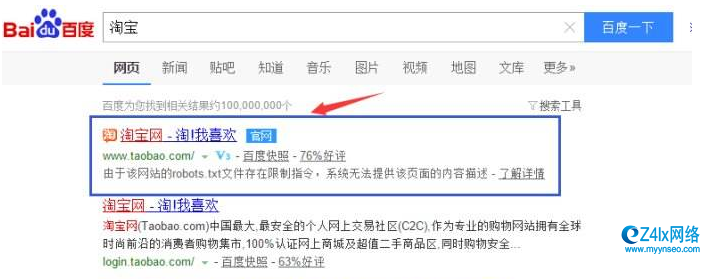
下图中淘宝的robots文件表示禁止百度蜘蛛抓取网站的任何内容,有人会问“我搜索淘宝网,明明可以搜到,难道是淘宝写错,或百度没有遵守这个规则?”这里长春seo的小编要说明两点:
(1)淘宝并没有写错
(2)百度有时候的确会不遵守规则,包括其他搜索引擎也是如此。
搜索引擎并不会完全遵守robots 文件,但总体来说都是遵守的。有些文章已经被百度收录了,如果临时要用robots 文件屏蔽它们,那么在百度的数据库里大概需要几个星期到一两个月的时间才能慢慢删除这些文章。
为什么淘宝网一直在百度里呢? 并不是百度不遵守规则,而是从用户体验的角度来讲,如果一个网民去百度搜索“淘宝网”,最后竟然搜索不到,他会认为百度这么大一个搜索引擎居然搜索不到这个知名的淘宝网,非常奇怪。所以像淘宝网这种非常知名的网站,百度对它比较特殊,或者说是从用户体验的角度出发,让网民能搜索到这类知名的网站,哪怕淘宝的robots文件里禁上百度抓取。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。